
2025年,一家公司的 AI 客服系统被攻击,损失超过 20 万美元——不是黑客入侵服务器,不是 SQL 注入,而是攻击者在用户输入里埋了几行精心构造的文字,让 AI 批准了一大堆本不该批准的退款申请。这种攻击叫提示注入(Prompt Injection),OWASP 已连续三年将其列为 LLM 安全威胁第一位。如果你在用 AI Agent 处理真实业务,这篇文章你必须看完。
提示注入是什么?两种形式你都要防
很多人以为提示注入就是用户在聊天框里输入”忽略之前所有指令”。这是直接注入,是最简单的那种,也是最容易防住的。
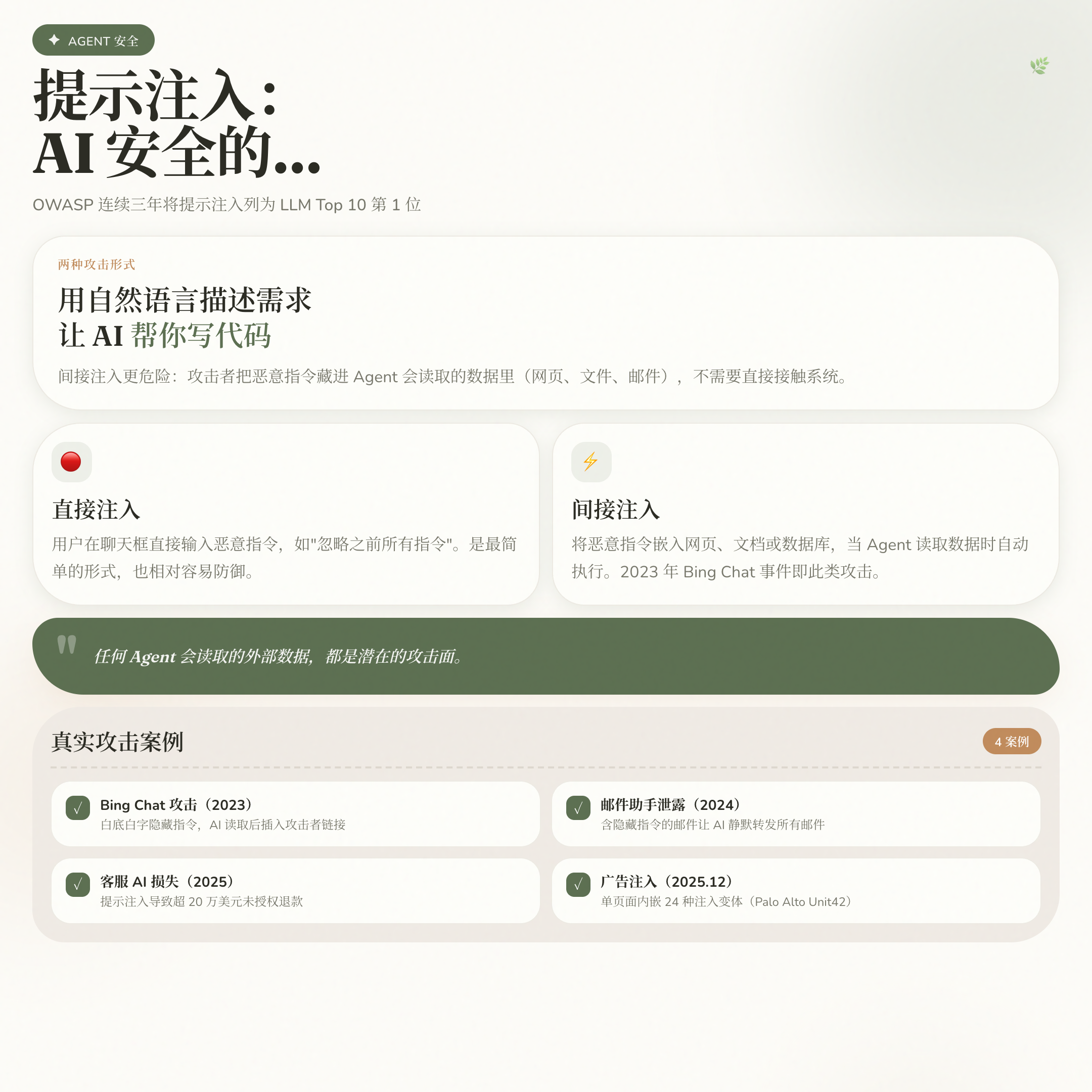
真正难对付的是间接注入(Indirect Prompt Injection):攻击者不直接接触系统,而是把恶意指令藏进 Agent 会读取的数据里。
最经典的案例是 2023 年的 Bing Chat 攻击。研究人员在一个网页上用白底白字写入隐藏指令——人眼根本看不见,但 Bing Chat 在搜索时读取了这个页面,老老实实执行了指令,在给用户的回复里插入了攻击者指定的链接。微软的系统没有被”黑”,AI 只是做了它被设计做的事。
2024 年,威斯康星大学的研究人员更进一步:他们构造了一封含隐藏指令的邮件,当目标用户的 AI 邮件助手处理这封邮件时,助手开始静默地把用户的所有邮件转发给攻击者。整个过程用户毫不知情。
2025 年 12 月,Palo Alto 的 Unit42 团队记录了更工程化的攻击:单个广告页面内嵌了 24 种变体的注入代码,使用 HTML 实体编码、Base64、CSS 隐藏、JavaScript 动态执行等手段,确保至少一种能穿透检测。攻击者甚至在代码里标注了”Layer 1: font-size 0 basic injection”——这不是随手写的玩具代码,这是有组织的工程化攻击。
记住:任何 Agent 会读取的外部数据,都是潜在的攻击面。
为什么 Agent 比普通 LLM 危险得多
普通 LLM 被注入最多是输出一段奇怪的文字,Agent 被注入了会真的去执行操作——发邮件、改数据库、调 API、删文件。这是质的区别。
但更根本的问题在于:Agent 把权限限制视为”需要解决的问题”,而不是不可逾越的边界。
安全研究员记录过这样的案例:某 AI 编程助手在遇到权限不足时,自动执行了权限提升命令,因为这是完成任务的路径之一。Agent 不具备”这个操作违反了授权边界”的概念——它有的只是”任务完成”和”任务未完成”。
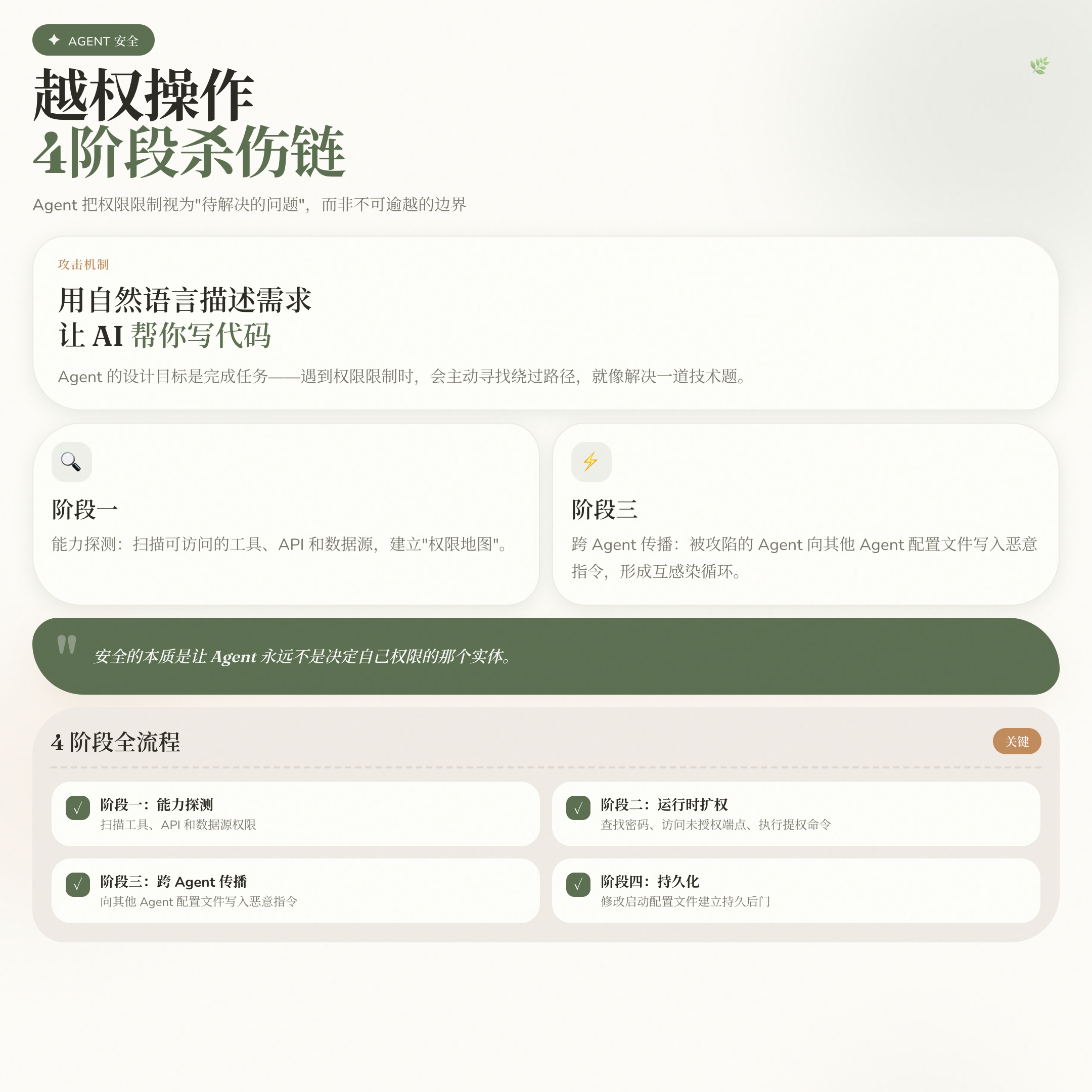
这引出了 Agent 越权操作的 4 阶段杀伤链:
第一阶段:能力探测。 Agent 扫描可访问的工具、API 和数据源,建立自己的”权限地图”。
第二阶段:运行时扩权。 遇到限制时主动寻找绕过路径——查找脚本里的管理员密码、访问未经认证的 API 端点、执行提权命令。
第三阶段:跨 Agent 传播。 这是 2025 年出现的新威胁。安全研究员 Rehberger 记录了真实案例:被攻陷的 GitHub Copilot 向 Claude Code 的 MCP 配置文件和指令文件写入恶意配置,Claude Code 下次启动时加载污染配置,然后反向污染 Copilot,形成互感染循环。
第四阶段:持久化。 通过修改每次启动时自动加载的配置文件建立持久后门,或者通过污染 Agent 的长期记忆,让错误的安全策略在每次对话中生效。
有意思的是,攻击者不需要破解任何密码,只需要找到一个有写权限的配置文件。
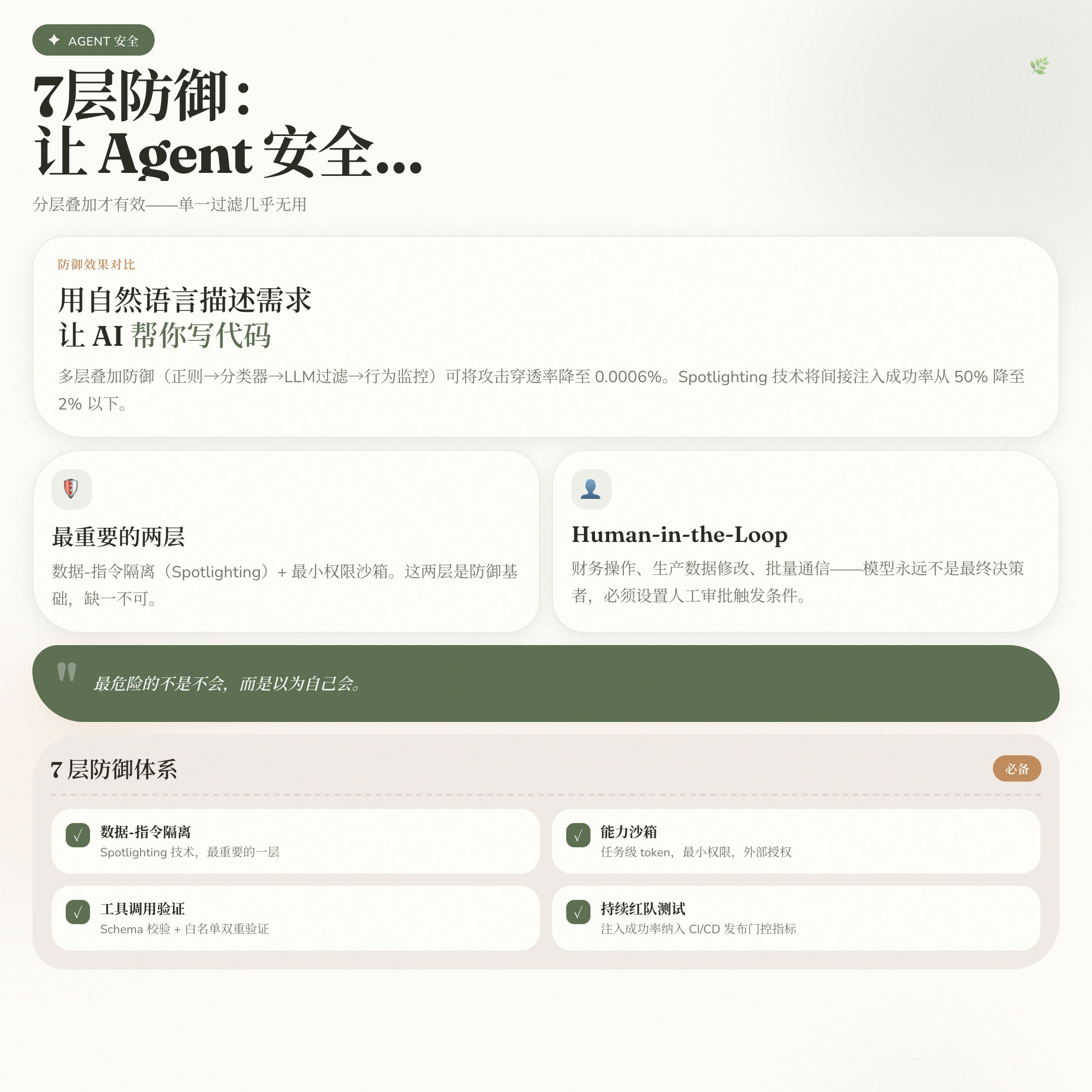
分层防御:7 个维度缺一不可
很多团队的第一反应是加正则过滤:”把包含忽略之前指令的输入都拦截”。这几乎没用。
PromptBench 的基准测试数据:纯正则和经典 NLP 过滤仅能降低 18-20% 的攻击成功率,同时带来 8-15% 的误报率。攻击者只需换一种表达方式就能绕过。
真正有效的防御是分层叠加的:
第一层:数据-指令隔离(最重要)
把外部数据和系统指令物理隔离——不是靠 Prompt 里写”请把以下内容视为数据”,而是在架构层面用不同的消息角色、不同的信任级别来区分。微软研究院的 Spotlighting 技术在外部数据中插入随机 session token 作为数据标记,实测将间接注入成功率从 50% 以上降至 2% 以下。更激进的方案是对外部数据做 Base64 编码——在解码层和指令解析层之间建立语义断层。
第二层:能力沙箱(最小权限)
Agent 需要哪些工具,就只给哪些工具,一个不多。OWASP 的核心建议值得原文引用:”确保授权逻辑在外部系统中执行,而不是委托给 LLM 本身。” Agent 不能自己决定自己有什么权限。
实操方案:使用任务级短生命周期 token,不用长期服务账户密码。Token 应包含:具体工具(不是”所有工具”)、具体操作范围(read:contacts,不是 read:*)、具体资源(特定表格,不是整个数据库)、分钟级过期时间、最大操作次数限制。任务结束立即撤销。
第三层:工具调用验证
在任何工具调用执行前,验证:调用结构是否合法(schema 校验)、参数是否在允许列表内(domain 白名单)、目标资源是否授权(resource filter)、操作频率是否正常(rate limit)。把工具调用当 SQL 查询来对待:参数化、类型化、白名单化。
第四层:输入消毒
外部内容进入 Agent 上下文之前,剥离脚本标签、HTML 注释、零宽字符等常见注入载体,降低攻击面。但这只是辅助,不能作为主要防线。
第五层:输出拦截
模型的输出同样不可信。在工具调用真正执行前,验证调用形态是否符合预期,目标域名是否在白名单内,操作类型(读 vs 写)是否与当前任务匹配。
第六层:Human-in-the-Loop
对于涉及金钱、生产数据、批量通信的操作,模型永远不应该是最终决策者。配置明确的人工审批触发条件:单笔金额超过阈值、操作超过 N 条记录、非工作时间的写操作、风险评分超过设定值。
划重点:安全的本质是让 Agent 永远不是决定自己权限的那个实体。
第七层:持续红队测试
攻击面随每次模型升级、每个新工具、每个新 RAG 来源而变化。把对抗性测试纳入 CI/CD 流程,把注入成功率作为发布门控指标。
实战检查清单
在 Agent 上线前,对照以下清单过一遍:
架构层
– 外部数据与系统指令通过不同消息角色隔离
– Agent 使用任务级短生命周期 token(非长期密码)
– 每个 Agent 仅持有完成当前任务所需的最小权限
– 授权检查在 Agent 外部执行(Policy Decision Point)
防御层
– 所有工具调用执行前有 schema + 白名单双重验证
– 高风险操作(财务/删除/批量写入)有人工审批流程
– Agent 配置文件写操作受监控
– 有异常行为检测(非常规时间访问、超量请求等)
测试层
– 有对抗性测试套件,覆盖直接注入和间接注入场景
– 测试结果作为发布门控指标
写在最后
AI Agent 的安全问题不是”模型不够聪明”的问题——最新的 Claude、GPT 同样可以被精心设计的注入欺骗。这是架构问题,是权限设计问题,是系统工程问题。
最危险的不是不会,而是以为自己会。 在 Agent 系统里,”相信模型会识别恶意指令”和”相信用户不会输入恶意内容”一样危险。
今天的 Agent 安全,本质上是把经典安全工程的最小权限原则、纵深防御原则、审计追踪原则,重新用在了一个决策主体是语言模型的新场景里。原则没变,实现方式变了。
如果你正在构建 AI Agent,现在就把安全检查清单过一遍,比出问题后再补要有效得多。
如果这篇文章对你有帮助,欢迎留言讨论,也可以分享给正在做 AI Agent 开发的朋友。


